
Algoritmo abusón
El algoritmo abusón es un método, dentro de la computación distribuida, para la elección dinámica de un coordinador según el ID de los procesos. El proceso con el ID mayor será seleccionado como el coordinador del sistema distribuido.
Es un algoritmo parecido al de Anillo, ya que utiliza mensajes de elección, respuesta y coordinación para determinar al nodo líder.
Premisas[editar]
- El sistema es síncrono y utiliza tiempo de espera para la identificación de fallos en los procesos.
- Se permite que los procesos se bloqueen/caigan durante la ejecución del algoritmo.
- La entrega de mensajes entre procesos se supone fiable.
- Los IDs de los procesos deben ser conocidos.
Comparado con el Algoritmo en Anillo:
- Se supone que el sistema es síncrono.
- Utiliza el tiempo de espera para detectar fallos/caídas en los procesos.
- Cada proceso conoce qué procesos tienen el ID más alto que el suyo y puede comunicarse con ellos.[1]
Tipos de mensaje[editar]
- Mensaje de Elección: Enviados para comunicar que se va a seleccionar un nuevo coordinador.
- Mensaje de Respuesta: Encargados de responder al mensaje de elección.
- Mensaje de Coordinador: Enviado para comunicar el ID del proceso seleccionado.
Funcionamiento del algoritmo[editar]
Cuando un proceso P detecta que el coordinador actual, por mensaje de tiempo de espera o fallo, está caído o bloqueado, se encarga de iniciar unas elecciones, este procedimiento se encargará de elegir el nuevo coordinador realizando las siguientes acciones: (Hay que tener en cuenta que es posible que varios procesos puedan descubrir la caída del coordinador de forma concurrente).
- P emite un mensaje de elección a todos los demás procesos con ID de proceso más alto, esperando un "estoy aquí" (mensaje de respuesta u OK) como respuesta de los procesos aún activos.
- Si P no recibe ninguna contestación de algún proceso cuyo ID sea superior, automáticamente es elegido como coordinador y multidifunde al resto de procesos que es el nuevo coordinador (mensaje de coordinador).
- Si P recibe una contestación de un proceso con ID más alto, P espera una cierta cantidad de tiempo para que el proceso multidifunda el mensaje comunicando al resto de procesos que ahora es él el coordinador. Si no recibe este mensaje a tiempo, reenvía el mensaje de elección.
- Si P recibe un mensaje de elección de otro proceso con un ID menor, envía un mensaje "estoy aquí" de vuelta y empieza de nuevo la elección de coordinador.
Aquel proceso con identificador más alto (el más "grandullón") es el que se hace coordinador. De esto le viene el nombre al algoritmo - un proceso con un ID más alto intimida a un proceso con un ID más bajo. Hay que tener en cuenta que si P recibe un mensaje de coordinador de un proceso con un ID más bajo, inmediatamente inicia una nueva elección.
-
 El Proceso 4 detecta que el Coordinador (Proceso 7) está caído.
El Proceso 4 detecta que el Coordinador (Proceso 7) está caído. -
 El Proceso 4 notifica a los procesos con un ID superior que el Coordinador está caído.
El Proceso 4 notifica a los procesos con un ID superior que el Coordinador está caído. -
 Los procesos que están vivos y han recibido el mensaje, devuelven un OK.
Los procesos que están vivos y han recibido el mensaje, devuelven un OK. -
 Los Procesos 5 y 6 repiten los pasos efectuados por el Proceso 4.
Los Procesos 5 y 6 repiten los pasos efectuados por el Proceso 4. -
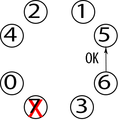 El Proceso 6 envía OK al proceso 5 y detecta que es el proceso con mayor ID.
El Proceso 6 envía OK al proceso 5 y detecta que es el proceso con mayor ID. -
 Como el Proceso 6 es el que tiene el mayor ID se proclama Coordinador y se lo comunica al resto de procesos.
Como el Proceso 6 es el que tiene el mayor ID se proclama Coordinador y se lo comunica al resto de procesos.






Procesos[editar]
Si un proceso sabe que tiene el ID más alto:
- Se elige a sí mismo coordinador enviando el mensaje coordinador a todos los procesos cuyo ID sea más bajo (proceso abusón).
- Si no tiene el ID más alto:
- Multidifunde el mensaje de elección entre todos los procesos con el ID más alto y espera un mensaje respuesta.
- Si tras un tiempo T no recibe ningún mensaje respuesta, se elige a sí mismo como coordinador.
- Si recibe un mensaje respuesta, espera un mensaje coordinador.
- Si recibe un mensaje coordinador, almacena el ID del nuevo coordinador.
- Si no recibe ningún mensaje, comienza una nueva elección.
- Si un proceso se recupera, o se lanza un proceso sustituto con el mismo ID, éste comienza una nueva elección, aunque el coordinador actual esté funcionando.
Características[editar]
- Cumple la Pervivencia del sistema distribuido, ya que todos los procesos conocen el identificador del coordinador al finalizar el proceso de elección.
- Presenta algunos problemas de Seguridad del sistema distribuido:
- Si se cae el proceso P (coordinador), pero se recupera al mismo tiempo que otro proceso Q decide ser el coordinador, algún proceso puede recibir dos mensajes coordinador con distintos identificadores.
- Los valores de los tiempos de espera son imprecisos (el sistema no es síncrono).
Rendimiento[editar]
| Mejor caso | Peor caso |
|---|---|
| El proceso con el segundo identificador más alto detecta el fallo del coordinador | El proceso con identificador más bajo detecta el fallo del coordinador |
N-2 mensajes coordinador |
O(N2) |
Puntos adicionales[editar]
1. Detección de Fallos y Recuperación
Detección de Fallos: Los procesos deben tener mecanismos robustos para detectar fallos del coordinador actual. Esto típicamente implica el uso de mensajes de latido (heartbeats) y temporizadores para determinar la falta de respuesta del coordinador.
Recuperación de Fallos: Es crucial describir cómo los procesos recuperados vuelven a integrarse en el sistema y cómo manejan la posibilidad de que un nuevo coordinador ya haya sido seleccionado durante su ausencia.
2. Optimización del Tiempo de Espera
Ajuste Dinámico: Los tiempos de espera pueden ser ajustados dinámicamente en función de las condiciones de red y carga del sistema para minimizar el tiempo de inactividad y el número de elecciones innecesarias.
Algoritmos de Backoff: Implementar algoritmos de backoff exponencial para evitar congestión en la red durante la fase de elección cuando múltiples procesos inician elecciones simultáneamente.
3. Manejo de Mensajes Redundantes
Filtrado de Mensajes: Para mejorar la eficiencia, los procesos pueden filtrar mensajes duplicados o innecesarios. Por ejemplo, si un proceso recibe múltiples mensajes de elección del mismo proceso, puede ignorar los duplicados.
Confirmación de Recepción: Utilizar confirmaciones de recepción (acknowledgments) para asegurar que los mensajes críticos han sido entregados y procesados.
4. Sincronización de Relojes
Sincronización de Relojes: Aunque el sistema es síncrono, es importante mencionar cómo se maneja la sincronización de relojes entre los procesos para asegurar que los tiempos de espera y los mensajes se manejan de manera coherente.
5. Escalabilidad y Rendimiento
Escalabilidad:
Desafíos: A medida que el número de procesos en el sistema aumenta, la cantidad de mensajes necesarios para coordinar y elegir un nuevo líder también crece, lo que puede llevar a congestión de red y mayores tiempos de latencia.
Optimización: Una posible optimización es el uso de jerarquías o clústeres de procesos. Cada clúster puede tener su propio coordinador local, y solo los coordinadores de los clústeres participan en la elección del coordinador global, reduciendo así la sobrecarga de mensajes.
Análisis de Rendimiento:
Latencia: La latencia en la elección de un nuevo coordinador puede ser significativa si hay muchos procesos con IDs más altos a los que se debe esperar una respuesta. Utilizar técnicas de reducción de latencia, como la paralelización de mensajes, puede ser útil.
Sobrecarga de Mensajes: Para minimizar la sobrecarga de mensajes, se pueden implementar mecanismos de supresión de mensajes redundantes y utilizar un enfoque de difusión controlada para los mensajes de elección y respuesta.
6. Comparación con Otros Algoritmos
Comparación Detallada:
Algoritmo en Anillo: En el Algoritmo en Anillo, los procesos están organizados en un anillo lógico, y los mensajes de elección se pasan de un proceso al siguiente hasta que todos los procesos han sido notificados. Esto puede ser menos eficiente en redes grandes debido a la latencia acumulada por cada salto en el anillo. Ventajas del Algoritmo Abusón: Es más rápido en redes con alta conectividad porque los mensajes de elección se envían directamente a todos los procesos con IDs más altos simultáneamente, en lugar de en una secuencia en anillo. Desventajas: La sobrecarga de mensajes puede ser mayor en el algoritmo abusón si hay muchos procesos con IDs más altos. Casos de Uso:
Algoritmo Abusón: Es ideal en sistemas donde la detección rápida del fallo de un coordinador y la elección de un nuevo coordinador es crítica, y donde los IDs de los procesos son únicos y conocidos. Algoritmo en Anillo: Es útil en sistemas donde la estructura en anillo ya está en uso para otras funciones de coordinación o en sistemas con menor número de procesos.
Referencias[editar]
- ↑ Jean Dollimore, Tim Kindberg, George F. Coulouris, "Distributed systems : concepts and design (Third Edition)," in Distributed systems : concepts and design (Third Edition). Addison-Wesley, 2003.
Bibliografía[editar]
- Witchel, Emmett (2005). "Distributed Coordination". Retrieved May 4, 2005.
- Hector Garcia-Molina, Elections in a Distributed Computing System, IEEE Transactions on Computers, Vol. C-31, No. 1, January (1982) 48-59
- G. Colouris, J. Dollimore, T. Kindberg and G. Blair. Distributed Systems: Concepts and Design (5th Ed). Addison-Wesley, 2011
| Control de autoridades |
|
|---|
 Datos: Q694171
Datos: Q694171 Multimedia: Bully algorithm / Q694171
Multimedia: Bully algorithm / Q694171