
Usuario:TheHandWritter87/PROYECTO
Comparación entre los diferentes enfoques de la traducción automática.[editar]
Los algoritmos de traducción automática pueden clasificarse atendiendo a su principio operativo. La TA puede basarse en un conjunto de reglas lingüísticas o en conjuntos amplios (corpus) de textos paralelos existentes. Las metodologías basadas en reglas pueden consistir en una traducción directa palabra por palabra, o operar a través de una representación más abstracta de significado: una representación específica del par de lenguas, o un interlingua independiente del lenguaje. Las metodologías basadas en corpus se basan en el aprendizaje automático y pueden seguir ejemplos específicos extraídos de textos paralelos, o calcular probabilidades estadísticas para seleccionar una opción más preferible de entre todas las traducciones posibles.
Traducción automática basada en reglas/corpus.[editar]
La traducción automática basada en reglas (por sus siglas en inglés, RBMT) se genera a partir del análisis morfológico, semántico y sintáctico de las lenguas de origen y meta. La traducción automática basada en corpus (por sus siglas en inglés, CBMT) se genera en base al análisis de corpus de texto bilingüe. La primera pertenece al ámbito del racionalismo, mientras que la segunda proviene de un enfoque más empírico. Una vez introducidas reglas lingüísticas tanto de uso común como específicas, los sistemas de RBMT son capaces de traducir con una calidad razonable, pero la creación de un sistema como este requiere mucho tiempo y esfuerzo, ya que dichos recursos lingüísticos deben crearse manualmente, lo que normalmente se conoce como problema de adquisición de conocimientos. Además, es muy difícil corregir o añadir nuevas reglas al sistema para generar una traducción. Por el contrario, añadir más ejemplos a un sistema de CBMT puede, de hecho, mejorar el sistema, dado que está basado en datos, aunque recopilar y gestionar un enorme corpus de datos bilingüe también puede ser costoso.
Traducción automática directa/mediante transferencia/mediante lenguaje intermedio.[editar]
Los métodos de traducción automática directa , mediante transferencia y mediante lengua intermedia o interlingua pertenecen al campo de la RBMT, pero difieren en la profundidad del análisis de la lengua origen y en la medida en que intentan alcanzar una representación, independiente del lenguaje, del significado o la intencionalidad entre la lengua origen y la lengua meta. Sus diferencias se pueden observar fácilmente mediante el triángulo de Vauquois, que ilustra estos niveles de análisis.
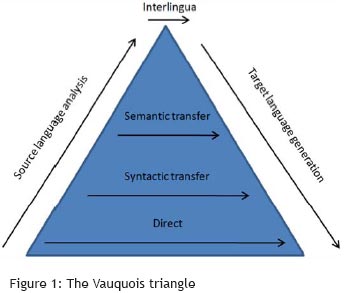{kind=link}
En su base, correspondiente al rango más superficial, la transferencia directa se realiza a nivel léxico. La traducción automática directa es un enfoque de traducción palabra por palabra con algunos ajustes gramaticales simples, en base al hallazgo de correspondencias directas entre unidades léxicas de las lenguas origen y meta. Cada sistema de traducción automática directa se diseña para un par de lenguas específico y cuya unidad de traducción suele ser la palabra.
Más arriba en la pirámide, la traducción se realiza mediante representaciones de la estructura oracional y el significado del texto origen mediante enfoques de transferencia sintáctica y semántica respectivamente. Un sistema de traducción automática mediante transferencia consta de tres etapas: la primera de ellas realiza el análisis del texto origen y lo convierte en representaciones abstractas; la segunda, en representaciones equivalentes orientadas al idioma de destino; y la tercera, en el texto meta final. Esta representación es específica para cada par de lenguas. La estrategia de transferencia puede ser vista como "un compromiso práctico entre el uso eficiente de los recursos propio de los sistemas interlingua, y la facilidad de implementación de los sistemas directos".
Por último, en el nivel superior, el concepto de transferencia se sustituye por el de interlingua o traducción automática mediante lengua intermedia, que opera en dos fases:
- La fase de análisis: consiste en la deconstrucción del texto origen en una representación del significado abstracta e independiente del lenguaje, es decir, la interlingua.
- La fase de síntesis: alude a la generación de un significado a partir de dicha representación mediante las unidades léxicas y construcciones sintácticas de la lengua meta.
Teóricamente, cuanto mayor sea el triángulo, más sencillas resultan estas fases. Por ejemplo, para traducir una lengua origen a n lenguas meta, se necesitan 1+n pasos usando una interlingua frente a los n pasos mediante transferencia; pero para traducir todas las lenguas, solo se necesitan 2n pasos mediante interlingua, en comparación con los n² que necesitaríamos con el enfoque mediante transferencia. Aunque no es necesario crear un componente de transferencia para cada par de lenguas al adoptar el enfoque de traducción automática mediante lengua intermedia, es terriblemente complicado definir una interlingua, e incluso tal vez imposible en un ámbito más extenso.
Traducción automática estadística y basada en ejemplos.[editar]
La traducción automática estadística (SMT según sus siglas en inglés) se genera a partir de modelos estadísticos cuyos parámetros se derivan del análisis de corpus de texto bilingüe. El modelo inicial de SMT basado en el teorema de Bayes, propuesto por Brown et al., considera que cada oración en un idioma es una posible traducción de cualquier oración en otro, y que la traducción más apropiada es aquella a la que el sistema le asigne la probabilidad más alta. La traducción automática basada en ejemplos (en inglés Example-based machine translation, EBMT) se caracteriza por el uso de un corpus bilingüe con textos paralelos como conocimiento principal, y toma como proceso protagonista la traducción por analogía. Este proceso consta de cuatro tareas: adquisición de ejemplos, creación y gestión del corpus, aplicación de patrones y síntesis.
Ambas pertenecientes a la CBMT, a veces denominada traducción automática basada en datos, la EBMT y la SMT tienen ciertos rasgos en común que las diferencian del la RBMT.
- Ambas utilizan un bitexto como fuente de datos esencial.
- Ambas son empíricas, aceptando el principio de aprendizaje automático, en lugar del principio racionalista de que los lingüistas escriban las reglas.
- Ambas pueden mejorarse obteniendo más datos.
- Pueden desarrollarse nuevos pares de lenguas simplemente encontrando otros corpus paralelos de datos adecuados, si los hubiese.
Aparte de estas similitudes, ambos sistemas presentan también algunas diferencias. La SMT utiliza esencialmente datos estadísticos tales como parámetros y probabilidades derivadas del bitexto, en los que el preprocesamiento de los datos es esencial, e incluso si el texto de búsqueda se encuentra en los datos de aprendizaje, no se puede garantizar que se produzca la misma traducción. Sin embargo, la EBMT utiliza el bitexto como su fuente primaria, en la que el preprocesamiento de datos es opcional y, si el texto de búsqueda se encuentra en el conjunto de ejemplos, debe producirse esa misma traducción.
Véase también[editar]
- Traducción automática.
- Traducción automática basada en reglas (EN).
- Traducción automática mediante transferencia.
- Traducción automática mediante interlingua.
- Traducción automática estadística.
- Traducción automática basada en ejemplos.
Referencias[editar]
- Nano Gough and Andy Way. 2004. Example-Based Controlled Translation. In Proceedings of the Ninth EAMT Workshop, Valletta, Malta, pp. 73–81.
- Jean, Senellart (2006). Boosting linguistic rule-based MT system with corpus-based approaches.
- A, Lampert (2004). «Interlingua in Machine Translation». Technical Report.
- Reshef, Shilon (2011). Transfer-based Machine Translation between morphologically-rich and resource-poor languages: The case of Hebrew and Arabic.
- Somers, H. (1999). «Review Article: Example-based Machine Translation». Machine Translation 14 (2): 113-157. doi:10.1023/a:1008109312730.
- Trujillo, A. (1999). Translation Engines: Techniques for Machine Translation. London: Springer.
- Andy, Way; Nano Gough (2005). «Comparing Example-Based and Statistical Machine Translation». Natural Language Engineering.
[[Categoría:Traducción automática| ]]