
Metagenómica

La metagenómica[1] se define como el estudio del material genético, el cual es obtenido directamente de muestras ambientales. Este amplio campo también puede ser conocido como genómica ambiental, ecogenómica o genómica de la comunidad.[2]
Por otro lado, la microbiología tradicional, la secuenciación del genoma microbiano y la genómica están basadas en la clonación. Las primeras secuenciaciones génicas clonaban genes específicos (normalmente el gen del ARNr 16S) para producir un perfil específico de la diversidad en una muestra natural. Dicho trabajo reveló que la gran mayoría de la biodiversidad microbiana se había perdido debido a los métodos basados en el cultivo.[3] Estudios recientes, usando tanto secuenciación escopeta como el método de secuenciación de PCR dirigido para obtener muestras no alteradas de todos los genes de todos los miembros de la comunidad de la muestra tomada.[4] Debido a su habilidad para revelar la vida microscópica previa escondida, la metagenómica ofrece una manera poderosa de poder ver y conocer el mundo microbiano que tiene el potencial de revolucionar el entendimiento de todo el mundo vivo.[5] Como el precio de la secuenciación de ADN sigue cayendo, la metagenómica ahora permite investigar la ecología microbiana a mayor escala y con mejor detalle que antes.
Etimología[editar]
El término "metagenómica" fue utilizado por primera vez por, entre otros, Jo Handlesman, Jon Clardly y Robert M. Goodman. Fue en 1998 cuando apareció por primera vez en una publicación científica.[6] El término metagenoma hacía referencia a un abordaje que pretendía analizar una colección de genes secuenciados de una muestra ambiental como si se tratara de un único genoma. Recientemente, Kevin Chen y Lior Pachter (investigadores de la Universidad de California, en Berkeley), definieron la metagenómica como «la aplicación de técnicas genómicas modernas para el estudio directo de comunidades de microorganismos en su entorno natural, evitando la necesidad de aislar y cultivar cada una de las especies que componen la comunidad».[7]
Historia[editar]
La secuenciación convencional comienza con un cultivo de células idénticas como fuente de ADN. Sin embargo, los primeros estudios metagenómicos revelaron que hay muchos grupos de microorganismos en diferentes ambientes que no pueden ser cultivados y por lo tanto no pueden ser secuenciados. Estos primeros estudios se concentraban en las secuencias de ARN ribosomal 16S que son relativamente cortas, normalmente conservada dentro de una especie, y generalmente diferente entre especies Muchas secuencias del ARNr 16S que han sido encontradas no corresponden a ninguna especie cultivada, indicando que hay una gran cantidad de organismos que no han sido aislado. Estos estudios de los genes de ARNr que se toman directamente del medio ambiente revelaron que los métodos de cultivos básicos encuentran menos del 1% de las bacterias y arqueas en una muestra.[3] Gran parte del interés en la metagenómica viene de estos descubrimientos, que demostraron que la gran mayoría de los microorganismos han pasado desapercibidos.
Los primeros trabajos moleculares llevados a cabo en el campo fueron dirigidos por Norman R. Pace y sus colegas, quienes usaron PCR para explorar la diversidad de las secuencias de ARN ribosomal.[8] La percepción que se obtuvo a partir de estos estudios tan avanzados condujeron a Pace a proponer la idea de clonar ADN directamente de muestras del medio ambiente a principios de 1985.[9] Esto condujo al primer reporte de aislamiento y clonación ADN desde muestras ambientales, publicado por Pace y sus colegas en 1991,[10] cuando Pace estaba en el Departamento de Biología en la Universidad de Indiana. Considerables esfuerzos aseguraron que no se tratase de falsos positivos del PCR y apoyaron la existencia de una comunidad compleja e inexplorada de especies. Aunque esta metodología estaba limitada a explorar genes no codificadores para proteínas que se conservan bastante, también ayudó a realizar las primeras observaciones microbianas basadas en la morfología demostrando que la diversidad era mucho más compleja que la conocida por los métodos de cultivo. Poco después de eso Healy reportó el aislamiento metagenómico de genes funcionales de "zoolibraries" construidas a partir de un cultivo complejo de organismos ambientales crecidos en un laboratorio en hierbas secas en 1995.[11] Tras dejar el laboratorio de Pace, Edward DeLong continuó en el campo y ha publicado trabajos que básicamente ha fijado las bases de trabajo para ofilogenias ambientales basado en la firma de secuencias 16S, empezando con la construcción de bibliotecas de muestras marinas por parte de su equipo.[12]
En 2002, Mya Breitbart, Forest Rohwer y sus colegas utilizaron la secuenciación de escopeta (ver abajo) para el ambiente para mostrar que 200 litros de agua de mar contienen más de 5000 virus diferentes.[13] Estudios subsiguientes demostraron que hay más de mil especies virales en las heces humanas y posiblemente un millón de virus diferentes por kilogramo de sedimento marino, incluyendo bacteriófagos. Básicamente todos los virus en estos estudios eran especies nuevas. En 2004, Gene Tyson, Jill Banfield, y sus colegas en University of California, Berkeley y el Joint Genome Institute secuenciaron el ADN extraído de un sistema de drenaje de minas de ácidos[14] Este esfuerzo resultó en los genomas completos o casi completos de un grupo de bacterias y arqueas que habían resistido intentos previos para ser cultivados.[15]
Empezando en el 2003, Craig Venter, líder del proyecto fundado de manera privada y paralelo al Proyecto del Genoma Humano, dirigió la Expedición Global Oceánica de Muestras (GOS), circunnavegando el globo y recolectando muestras metagenómicas durante todo el viaje. Todas estas muestras se secuenciaron usando secuenciación de escopeta, con la esperanza de que fueran identificados nuevos genomas (y por lo tanto nuevos organismos). El proyecto piloto, que se llevó a cabo en el mar de los Sargazos, encontró ADN de casi 2000 especies diferentes, incluyendo 148 tipos de bacterias nunca vistas anteriormente.[17] Venter ha circunnavegado el globo y explorado a fondo la costa Oeste de Estados Unidos, completó una expedición de dos años para explorar el mar Báltico, el mar Mediterráneo y el mar Negro. Los análisis de la información metagenómica recopilada durante dicho viaje revelaron dos grupos de organismos, uno compuesto de taxones adaptado para condiciones ambientales 'feast or famine', y un segundo compuesto de relativamente menos, pero más abundantes y mejor distribuidos taxones, compuestos principalmente de plankton.[18]
En el 2005 Stephan C. Schuster en Penn State University y sus colegas publicaron las primeras secuencias de una muestra ambiental generada mediante secuenciación de alto rendimiento, en este caso pirosecuenciación masiva y paralela desarrollada por 454 Life Sciences.[19] Otro trabajo que apareció a principios de estos estudios fue de Robert Edwards, Forest Rohwer, y sus colegas en el 2006 en San Diego State University.[20]
Secuenciación[editar]
La recuperación de secuencias de ADN mayores de unos pocas miles de pares de bases era muy difícil hasta la reciente llegada de avanzadas técnicas de biología molecular que permiten la construcción de genotecas de cromosomas artificiales bacterianos (BACs), que poseen numerosas ventajas como vectores, no presentes en los vectores de clonación disponibles hasta su aparición.[21]

Secuenciación[editar]
El poder recuperar secuencias de ADN más largas de unos cuantos miles pares de bases de muestras ambientales fue bastante difícil hasta avances recientes en las técnicas de biología molecular que permitieron la construcción de bibliotecas en cromosomas artificiales de bacteria, las cuales proporcionaban mejores vectores de la clonación molecular.[21]
Metagenómica de escopeta[editar]
Los avances en bioinformática, el refinamiento de las amplificaciones de ADN y la proliferación de poder computacional han ayudado significativamente al análisis de las secuencias de ADN recuperadas de muestras ambientales, permitiendo la adaptación de la secuenciación de escopeta a las muestras metagenómicas. La manera, que se usa para secuenciar muchos microorganismos cultivados y el genoma humano, es cortar aleatoriamente el ADN en muchas secuencias cortas y reconstruirlas en una secuencia de consenso. La secuenciación de escopeta revela los genes presentes en las muestras ambientales. Antes las bibliotecas de clonación se utilizaban para facilitar la secuenciación. Sin embargo, con los avances en las tecnologías de secuenciación de alto rendimiento la clonación ya no es necesaria y es posible obtener un mejor porcentaje de la información secuenciada prescindiendo de este paso, que es largo y tedioso. La metagenómica de escopeta proporciona información acerca de qué organismos están presentes y qué procesos metabólicos son posibles en la comunidad.[22] Como el conjunto de ADN de un ambiente es poco controlado, los organismos más abundantes en una muestra ambiental están representados mejor en los resultados de la secuenciación de información. Para lograr la mayor cobertura requerida para obtener los genomas de los miembros de comunidades poco representadas, a veces se usan muestras grandes, normalmente excesivamente costosas. Por otro lado, la naturaleza de aleatoriedad de la secuenciación de escopeta asegura que muchos de estos organismos, que de otra manera pasarían desapercibidos al utilizarse técnicas tradicionales de cultivo, serán representados por lo menos por algunos segmentos pequeños de la secuencia.[14]
Secuenciación de alto rendimiento[editar]
Los primeros estudios metagenómicos que se llevaron a cabo con la secuenciación de alto rendimiento usaron de manera paralela 454 pyrosequencing.[19] Otras tres tecnologías comúnmente utilizadas para el muestreo ambiental son Ion Torrent Personal Genome Machine, Illumina MiSeq o HiSeq y Applied Biosystems SOLiD.[23] Estas técnicas para la secuenciación de ADN generan fragmentos más cortos que la secuenciación de Sanger; Ion Torrent PGM System y 454 pyrosequencing normalmente producen lecturas de ~400 pares de bases, Illumina MiSeq produce lecturas de 400-700 pares de bases (dependiendo de si se usan las opciones de pareo de los extremos), y Applied Biosystems SOLiD produce lecturas de 25-75 pares de bases[24] Históricamente, estas longitudes de lecturas eran un poco más cortas de lo que lee la secuenciación de Sanger de ~750 pares de bases, pero la tecnología Illumina se está acercando rápidamente a este punto de referencia. No obstante, esta limitación es compensada por el mucho mayor número de secuencias leídas. En 2009, la pirosecuenciación de metagenomas generaba 200–500 megabases, y las plataformas de Illumina generaban alrededor 20–50 gigabases, pero estos resultados han aumentado en magnitudes considerables en los últimos años.[25] Una ventaja adicional de la secuenciación de alto rendimiento es que esta técnica no requiere clonar el ADN antes de secuenciar, evitando así uno de los procesos más largos y complicados del muestreo ambiental.
Bioinformática[editar]
La información generada por los experimento de la metagenómica es mucha e inheremente ruidosa, conteniendo información fragmentada que representa a más de 10,000 especies.[26] La secuenciación del genoma de la vaca rumiante generó 9 gigabases, o 279 mil millones pares de bases de nucleótidos secuenciados,[27] mientras que el catálogo de genes del microbioma del intestino humano identificó 3.3 mil millones de genes ensamblados de 567.7 gigabases información secuenciada.[28] La recogida, el tratamiento y la extracción de información biológica útil a partir de conjuntos de datos de este tamaño suponen importantes desafíos computacionales para los investigadores.[22][29][30]
Secuencia pre-filtrada[editar]
El primer paso del análisis de información metagenómica requiere la ejecución de ciertos pasos de pre-filtrado, incluyendo el quitar secuencias redundantes de baja calidad y secuencias de origen eucarionte (especialmente en metagenomas de origen humano).[31][32] Los métodos disponibles para quitar secuencias genómicas de ADN contaminantes y eucarióticas incluyen Eu-Detect y DeConseq.[33][34]
Ensamblaje[editar]
La información de secuencias de ADN de proyectos genómicos y metagenómicos son básicamente lo mismo, pero las secuencias genómicas ofrecen mayor cobertura mientras que la información metagenómica es normalmente muy no-redundante.[30] Así mismo, el incremento en el uso de tecnologías de segunda generación con longitudes de lectura cortas significa que una gran parte de la información metagenómica futura será propensa a errores. Combinando estos factores, hacen el ensamblaje de las lecturas de secuencias metagenómicas a genomas difíciles y poco confiables. Los ensamblajes mal hechos son ocasionados por la presencia de secuencias repetitivas del ADN que vuelven el ensamblaje especialmente difícil por la diferencia en la cantidad relativa de especies presentes en la muestra.[35] Los ensamblajes mal hechos también pueden incluir la combinación de secuencias de más de una especie a cóntigos quiméricos.[35]
Existen programas de ensamblaje, la mayoría de los cuales pueden usar la información de las etiquetas pareadas al final con el propósito de mejorar la precisión de los ensamblajes. Algunos programas, como Phrap o Celera Assembler, fueron diseñados para ensamblar genomas sencillos, pero generan buenos resultados al ensamblar información de conjuntos metagenómicos.[26] Otros programas, como Velvet assembler, han sido optimizados para las lecturas más cortas producidas por la secuenciación de segunda generación a través del uso de de Bruijn graphs. El uso de genomas de referencia permite a los investigadores mejorar el ensamblaje de las especies microbiales más abundantes, pero este acercamiento está limitado por el pequeño subconjunto de filos para los cuales hay genomas secuenciados disponibles.[35] Después de que se haga un ensamblaje, otro reto es "la deconvolución metagenómica", o determinar que secuencias vienen de que especies en la muestra.[36]
Predicción de genes[editar]
Los análisis metagénomicos de las fuentes de información utilixan dos acercamientos en la anotación de regiones codificantes en los cóntigos ensamblados.[35] El primer acercamiento es identificar los genes basándose en la homología con genes que ya estén públicamente disponibles en las bases de datos de secuencia, normalmente por simples búsquedas BLAST. Este tipo de acercamiento está implementado en el programa MEGAN4.[37] El segundo, ab initio, utiliza características intrínsecas de la secuencia para predecir las regiones codificantes basándose en conjuntos de genes de organismos relacionados. Este es el acercamiento tomado por programas comoGeneMark[38] y GLIMMER. La ventaja principal de la predicción ab initio es que permite la detección de regiones codificantes que no tengan homólogos en las bases de datos de secuencias, pero resulta más preciso cuando hay grandes regiones continuas de ADN genómico para comparación.[26]
Diversidad de especies[editar]
La anotación de genes proporciona el "que", mientras que las mediciones de la diversidad de especies proporcionan el "quien" .[39] Para poder conectar la función y la composición de la comunidad en metagenomas, las secuencias deben estar agrupadas. El agrupamiento es el proceso de asociar una secuencia en partículas con un organismo.[35] En métodos de agrupamiento por similitud como BLAST se usan para buscar rápidamente marcadores filogenéticos o de otro modo secuencias similares en las bases de datos públicas existentes. Este acercamiento es implementado en MEGAN.[40] Otra herramienta, PhymmBL, utiliza modelos interpolados de Markov para asignar lecturas.[26] MetaPhlAn y AMPHORA son métodos basados en marcadores de clados específicos para estimar la abundancia relativa con desempeños computacionales mejorados.[41] Una vez que las secuencias son agrupadas, es posible llevar a cambo análisis comparativos de la diversidad y la riqueza utilizando herramientas como Unifrac.[26]
Integración de la información[editar]
La cantidad masiva de información se secuenciación que no deja de crecer exponencialmente es un reto desalentador que se complica por la complejidad de la metadata asociada con proyectos metagenómicos. La Metadata incluye información detallada acerca de la geografía tridimensional y las características ambientales de la muestra, información física acerca del sitio de la muestra y la metodología del muestreo.[30] Dicha información es necesaria tanto para asegurar la replicabilidad como para permitir el análisis downstream.[42]
Se han desarrollado varias herramientas para integrar la metadata y la información de secuencias, permitiendo un análisis comparativo downstream de diferentes conjuntos de información mediante un número de índices ecológicos. En 2007, Folker Meyer y Robert Edwards y un equipo en Argonne National Laboratory en University of Chicago liberó el Metagenomics Rapid Annotation usando el servidor de Subsystem Technology (MG-RAST), un recurso comunitario para los análisis de conjuntos de metgagenomas.[43] Desde junio del 2012, han sido analizadas más de 14.8 terabases (14x1012 bases) de ADN, con más de 10,000 conjuntos de información pública disponible dentro de MG-RAST. Más de 8,000 usuarios han presentado un total de 50,000 metagenomas a MG-RAST. El sistema Integrated Microbial Genomes/Metagenomes (IMG/M) también proporciona una serie de herramientas para el análisis funcional de comunidades microbianas basado en su secuencia de metagenoma, basado en aislamiento de genomas como referencia incluida del sistema Integrated Microbial Genomes (IMG) y del proyecto Genomic Encyclopedia of Bacteria and Archaea (GEBA).[44]
Una de las primeras y en aquel entonces única herramienta para analizar un metagenoma por alto rendimiento de información obtenida de escopeta fue MEGAN (MEta Genome ANalyzer).[37][40] Una primera versión del programa fue usada en 2005 para analizar el contexto metagenómicos de secuencias de ADN obtenidas de un hueso de mamut.[19] Basado en una comparación en BLAST contra una base de datos de referencia, esta herramienta llevó a cabo tanto el reagrupamiento taxonómico como el funcional, al colocar las lecturas en los nodos de la taxonomía NCBI usando un simple algoritmo de ancestro menos común o en los nodos de SEED o KEGG.[45]
Metagenómica comparativa[editar]
Los análisis comparativos entre metagenomas pueden proporcionar una percepción adicional hacia la función de comunidades microbianas complejas y su papel en la salud del huésped.[46] Una comparación múltiple entre metagenomas puede hacerse a un nivel de la composición de la secuencia (comparando contenido GC o tamaño del genoma) taxonomía, diversidad o complemento funcional. Las comparaciones de las estructuras poblacionales y la diversidad filogenética pueden hacerse en la base de 16S y otros marcadores filogenéticos, o —en el caso de comunidades poco diversas— por reconstrucción de genoma del conjunto de información metagenómica.[47] Las comparaciones funcionales entre metagenomas pueden hacerse al comparar secuencias contra las referencias en las bases de datos como COG o KEGG, y tabulando la abundancia por categoría y evaluando cualquier diferencia por significación estadística.[45] Este acercamiento centrado en genes enfatiza el complemento funcional de la comunidad como uno, y no como grupos taxonómicos y demuestra que los complementos funcionales son análogos bajo condiciones ambientales similares.[47] Por consiguiente, la metadata en un contexto ambiental de las muestras metagenómicas es especialmente importante en análisis comparativos, ya que proporciona a los investigadores la habilidad de estudiar el efecto del hábitat sobre la estructura de la comunidad y la función.[26]
Además, varios estudios también han utilizado patrones de uso de oligonucleótidos para identificar las diferencias a través de diversas comunidades microbianas. Ejemplos de dichas metodologías incluyen el acercamiento de Willnet et al, la abundancia relativa del dinucleótido.[48] y el acercamiento de HabiSign por Ghosh et al.[49] Ghosh et al. (2011)[49] también indicó que diferencias en los patrones de uso pueden ser usadas para identificar genes (o lecturas metagenómicas) originándose en hábitats específicos. Además algunos métodos como TriageTools[50] o Compareads[51] detectan lecturas similares entre dos conjuntos de lecturas. La medida de similitud que aplican en las lecturas se basa en el número de palabras idénticas de longitud k compartido por pares de las lecturas.
Un objetivo clave en la metagenómica comparativa es poder identificar grupos microbianos que son responsables de otorgar características específicas a cierto ecosistema. Sin embargo, debido a problemas con las tecnologías de secuenciación de los artefactos deben considerarse como si fuera metagenomeSeq.[29] Otros han caracterizado interacciones inter-microbianas entre los grupos microbianos residentes.. Una aplicación de análisis comparativo metagenómicos basado en GUI llamada Community-Analyzer ha sido desarrollada por Kuntal et al.[52], que implementa una gráfica basada en una correlación y despliega un algoritmo que no solo facilita una visualización rápida de las diferencias en las comunidades microbianas analizadas (en términos de composición taxonómica), pero también proporciona una visión hacia las interacciones inherentes inter-microbianas que ocurren ahí. Notablemente, este algoritmo desplegado también permite la agrupación de los metagenomas basándose en los patrones inter-microbianos probables más que por simplemente comparar valores de abundancias de varios grupos taxonómicos. Además, la herramienta implementa diversas funcionalidades interactivas basadas en GUI que permiten a los usuarios realizar un análisis comparativo estándar a través de microbiomas..
Análisis de datos[editar]
Metabolismo de la comunidad[editar]
En muchas comunidades bacterianas, naturales o diseñadas (como bioreactores), hay una división significativa de trabajo en el metabolismo (sintropía), durante la cual los desechos de algunos organismos son metabolitos de otros.[53] En dicho sistema, la estabilidad funcional del bioreactor metanogénico requiere la presencia de varias especies sintrópicas. (Syntrophobacterales y Synergistia) trabajando juntas para poder convertir recursos crudos en residuos metabolizados completamente (metano).[54] Usando estudios de comparación de genes y experimento de expresión con microarreglos o investigadores de proteómica pueden crear una red metabólica que vaya más allá de las fronteras de las especies. Dicho estudio requiere un conocimiento detallado acerca de qué versiones de qué proteínas son codificadas por qué especies e, incluso, por qué tipos de qué especies. Por lo tanto, la información de la genómica de comunidad es otra herramienta fundamental (junto con la metabolómica y la proteómica) en la búsqueda para determinar cómo los metabolitos son transferidos y transformados por una comunidad.[55]
Metatranscriptómica[editar]
La metagenómica permite a los investigadores acceder la diversidad funcional y metabólica de comunidades microbianas, pero no puede demostrar cual de estos procesos está activo.[47] La extracción y los análisis del ARNm metagenómico (el metatranscriptoma) proporciona información sobre la regulación y perfiles de expresión de comunidades complejas. Debido a las dificultades técnicas (la corta vida media del ARNm, por ejemplo) presentes en la recolección de ARN ambiental, ha habido relativamente pocos estudios metatranscriptómicos in situ de las comunidades microbianas hasta la fecha.[47] Mientras que originalmente estaban limitados a la tecnología de microarreglos, los estudios metatranscriptómicos han usado directamente secuenciación de alto rendimiento del ADNc para proporcionar la expresión del genoma completa y cuantificación de una comunidad microbiana,[47] primero empleada por Leininger et al. (2006) en su análisis de oxidación de amoniaco en suelos.[56]
Virus[editar]
La secuenciación metagenómica resulta particularmente útil en el estudio de comunidades virales. Como los virus no tienen un marcador filogenético universal que compartan (como el ARN 16S para bacterias y arquea y el ARN 18S para eucariota), la única manera de acceder a la diversidad genética de la comunidad viral desde una muestra ambiental es a través de la metagenómica. La metagenómica viral debe poder proporcionar más y más información acerca de la diversidad viral y la evolución.[57] Por ejemplo, una fuente de información metagenómica llamada Giant Virus Finder aportó la primera evidencia de la existencia de virus gigantes en un desierto salino.[58]
Aplicaciones[editar]
La metagenómica tiene el potencial de avanzar el conocimiento en una gran variedad de campos. También puede aplicarse a la resolución de retos prácticos en medicina, ingeniería, agricultura, sostenibilidad y ecología.[30]
Medicina[editar]
Las comunidades microbianas juegan un papel clave en la preservación de la salud humana, pero su composición y el mecanismo por el que hacen esto sigue siendo un misterio.[59] La secuenciación metagenómica está siendo usada para caracterizar las comunidades microbianas de 15-18 sitios del cuerpo de por lo menos 250 individuos. Esto es parte de la Iniciativa del Microbioma Humano, con los objetivos principales de determinar si existe un microbioma humano central, entender los cambios en el microbioma humano que pueden correlacionarse con la salud humana y desarrollar nuevas herramientas tecnológicas y de bioinformática para poder alcanzar dichos objetivos.[60]
Otro estudio médico parte del proyecto MetaHit (Metagenómica de Tracto Intestinal Humano) consistió de 124 individuos de Dinamarca y España saludables, con sobrepeso y pacientes con síndrome del intestino irritable. El estudio intentó categorizar la profundidad y la diversidad filogenética de las bacterias gastrointestinales. Utilizando datos de secuenciación de Illumina GA y SOAPdenovo, de Bruijn, una herramienta basada en gráficas diseñada específicamente para ensamblar lecturas cortas, fueron capaces de generar 6.59 millones de cóntigos mayores a 500 pares de bases para un cóntigo de longitud total de 10.3 Gb y un N50 de 2.2 kb.
El estudio demostró que dos divisiones bacterianas, Bacteroidetes y Firmicutes, constituyen más del 90% de las categorías filogenéticas que dominan la bacteria intestinal. Usando las frecuencias relativas de los genes encontrados dentro del intestino, estos investigadores encontraron 1,244 agrupaciones metagenómicas que son críticamente importantes para la salud del tracto intestinal. Hay dos tipos de funciones en estas agrupaciones: gestión interna y las que son específicas para el intestino. Las agrupaciones de genes de gestión interna son necesarias en todas las bacterias y normalmente son componentes clave en los principales mecanismos metabólicos incluyendo el metabolismo central del carbono y la síntesis de aminoácidos. Las funciones específicas del intestino incluyen adhesión a proteínas huéspedes y la cosecha de azúcares a partir de los glicolípidos globoseries. Pacientes con el síndrome del intestino irritable exhibieron un 25% menos de genes y menor diversidad bacteriana que los individuos que no sufrían de la enfermedad, indicando que cambios en la diversidad de la bioma intestinal del paciente pueden estar asociados con esta condición.
Mientras estos estudio destacan algunas aplicaciones potenciales médicas importantes, solo 31-48.8% de las lecturas puede alinearse a 194 genomas públicos del intestino humano y 7.6-21.2% a los genomas de las bacterias disponibles en GenBank, lo cual indica que hace falta mucha más investigación para capturar los genomas bacterianos necesarios.[61]
Biocombustibles[editar]

Los biocombustibles son combustibles derivados de la conversión de biomasa, como en la conversión de celulosa contenida en tallos de maíza y otra biomasa en etanol celúlosico[30] Este proceso depende de los consorcios microbianos que transforman la celulosa en azúcares, seguido de la fermentación de los azúcares para formar etanol. Los microbios ambientan producen una variedad de fuentes de bioenergía incluyendo metano e hidrógeno.[30]
La deconstrucción eficiente a escala industrial de biomasa requiere enzimas nuevas con mayor productividad y menor costo.[27] Los acercamientos metagenómicos al análisis de comunidades microbianas complejas permite la proyección de enzimas con aplicaciones industriales para la producción de biocombustibles como las hidrolasas glicosídicas.[62] Además se require conocimiento de como la función de estas comunidades microbianas se requiere para controlaras y la metagenómica es la herramienta clave para entenderlas. Los acercamientos metagenómicos permiten análisis comparativos entre sistemas microbianos convergentes como fermentadores de biogás[63] o insectos herbívoros como el hongo del jardín de las hormigas cortahojas.[64]
Remediación Ambiental[editar]
La metagenómica puede mejorar las estrategias para monitorear el impacto de contaminantes en los ecosistemas y para limpiar los ambientes contaminados, un mejor entendimiento de como las comunidades microbianas se enfrentan con los contaminantes mejora las evaluaciones de los sitios potencialmente contaminados para recuperarlos e incrementar las oportunidades de los ensayo de bioaumentación y bioestimulación funcionen.[65]
Biotecnología[editar]
Las comunidades microbianas producen un arreglo de químicos biológicos activos que son usados en competencia y comunicación.[66] Muchos de los fármacos usados hoy en día fueron originalmente descubiertos en microbios; el progresos reciente explotando los ricos recursos genéticos de microbios no cultivables ha dirigido al descubrimiento de nuevos genes, enzimas y productos naturales.[47][67] La aplicación de la metagenómica ha permitido el desarrollo de productos, químicos finos y farmacéuticos donde el beneficio de la síntesis quiral de enzima catalizada es ampliamente reconocido.[68]
Dos tipos de análisis son usados en la bioprospección de la información metagenómica: la proyección impulsada por una función para una característica expresada y proyección impulsada en una secuencia para secuencias de ADN de interés.[69] Los análisis impulsados en una función buscan identificar clones expresando una característica deseada o una actividad útil, seguido por caracterización bioquímica y análisis de secuencia. Este acercamiento está limitado por la disponibilidad de una pantalla adecuada y el requisito de que la característica deseada debe estar expresada en la célula huésped. Además, el bajo rango de descubrimiento (menos de uno por cada 1,000 clones proyectados) y la intensa carga de trabajo que requiere limitan el acercamiento.[70] En contraste, los análisis impulsados por secuencia usan secuencias conservativas de ADN para diseñar los primers para PCR para proyectar clones para la secuencia de interés.[69] En comparación a los acercamientos basados en clonación, usar un acercamiento solo basado en la secuencia reduce la cantidad de exhibición requerida. La aplicación de secuenciación masiva paralela también aumenta de manera importante la cantidad de información de secuenciación generado, la cual requiere fuentes de análisis bioinformático de alto rendimiento.[70] El acercamiento impulsado por secuencia para proyectar está limitado por la amplitud y la precisión de las funciones de los genes presentes en bases de datos de secuencias públicas. En la práctica, en los experimentos se hace uso de una combinación de ambos acercamiento basados en la función de interés, la complejidad de la muestra a proyectarse y otros factores.[70][71]
Agricultura[editar]
Los suelos donde crecen las plantas están habitados por comunidades microbianas con un gramo de suelo conteniendo alrededor de 109-1010 células microbianas que comprenden cerca de una gigabase de información de secuencia.[72][73] Las comunidades microbianas que habitan suelos son de las más complejas conocidas por la ciencia, y permanecen poco entendidas a pesar de su importancia económica.[74] Los consorcios microbianos realizan una variedad de servicios ecológicos necesarios para el crecimiento de plantas, incluyendo fijar el nitrógeno de la atmósfera, el ciclo de nutrientes, supresión de enfermedades y secuestro de hierro y otro metales.[66] Las estrategias funcionales metagenómicas están siendo usadas en explorar la interacción entre plantas y microbios a través del cultivo independiente de las comunidades microbianas.[75] Al permitir una percepción de los papeles de miembros de la comunidad no cultivados en el ciclo de los nutrientes y la promoción del crecimiento de las plantas, los acercamientos metagenómicos puede contribuir a una mejor detección de enfermedades en cosechas y ganado y la adaptación de mejores prácticas agrícolas que mejoren la salud de las cosechas al aprovechar la relación entre los microbios y las plantas.[30]
Ecología[editar]
La metagenómica puede proporcionar una percepción muy importante hacia la ecología funcional las comunidades ambientales.[76] Los análisis metagenómicos del consorcio de bacterias encontrados en la defecación de los leones marinos australianos sugiere que las heces ricas en nutrientes de los leones marinos pueden ser un nutriente importante para ecosistemas costeros. Esto es porque las bacterias que son expulsadas simultáneamente con las heces son ideales para descomponer los nutrientes en las heces en una forma biodisponible que puede ser tomada en la cadena alimenticia.[77]
La secuenciación del ADN también puede ser usada de manera más amplia para identificar especies presentes en un cuerpo de agua,[78] los escombros filtrados del aire o una muestra de tierra. Esto puede establecer el rango de especies invasoras y especies en peligro al igual que rastrear poblaciones de temporada.
Véase también[editar]
Referencias[editar]
- ↑ Raúl de la Puente. Metagenómica. Esa valiosa desconocida Journal of Feelsynapsis (JoF). ISSN 2254-3651. 2013.(12): 60-65
- ↑ http://www.oei.es/divulgacioncientifica/reportajes_416.htm
- ↑ a b Hugenholz, P; Goebel BM; Pace NR (1 de septiembre de 1998). «Impact of Culture-Independent Studies on the Emerging Phylogenetic View of Bacterial Diversity». J. Bacteriol 180 (18): 4765-74. PMC 107498. PMID 9733676.
- ↑ Eisen, JA (2007). «Environmental Shotgun Sequencing: Its Potential and Challenges for Studying the Hidden World of Microbes». PLoS Biology 5 (3): e82. PMC 1821061. PMID 17355177. doi:10.1371/journal.pbio.0050082.
- ↑ Marco, D, ed. (2011). Metagenomics: Current Innovations and Future Trends. Caister Academic Press. ISBN 978-1-904455-87-5.
- ↑ Handelsman, J.; Rondon, M. R.; Brady, S. F.; Clardy, J.; Goodman, R. M. (1998). «Molecular biological access to the chemistry of unknown soil microbes: A new frontier for natural products». Chemistry & Biology 5 (10): R245-R249. PMID 9818143. doi:10.1016/S1074-5521(98)90108-9..
- ↑ Chen, K.; Pachter, L. (2005). «Bioinformatics for Whole-Genome Shotgun Sequencing of Microbial Communities». PLoS Computational Biology 1 (2): e24. PMC 1185649. PMID 16110337. doi:10.1371/journal.pcbi.0010024.
- ↑ Lane, DJ; Pace B; Olsen GJ; Stahl DA; Sogin ML; Pace NR (1985). «Rapid determination of 16S ribosomal RNA sequences for phylogenetic analyses». Proceedings of the National Academy of Sciences 82 (20): 6955-9. Bibcode:1985PNAS...82.6955L. PMC 391288. PMID 2413450. doi:10.1073/pnas.82.20.6955.
- ↑ Pace, NR; DA Stahl; DJ Lane; GJ Olsen (1985). «Analyzing natural microbial populations by rRNA sequences». ASM News 51: 4-12. Archivado desde el original el 4 de abril de 2012.
- ↑ Pace, NR; Delong, EF; Pace, NR (1991). «Analysis of a marine picoplankton community by 16S rRNA gene cloning and sequencing». Journal of Bacteriology 173 (14): 4371-4378. PMC 208098. PMID 2066334.
- ↑ Healy, FG; RM Ray; HC Aldrich; AC Wilkie; LO Ingram; KT Shanmugam (1995). «Direct isolation of functional genes encoding cellulases from the microbial consortia in a thermophilic, anaerobic digester maintained on lignocellulose». Appl. Microbiol Biotechnol. 43 (4): 667-74. PMID 7546604. doi:10.1007/BF00164771.
- ↑ Stein, JL; TL Marsh; KY Wu; H Shizuya; EF DeLong (1996). «Characterization of uncultivated prokaryotes: isolation and analysis of a 40-kilobase-pair genome fragment from a planktonic marine archaeon». Journal of Bacteriology 178 (3): 591-599. PMC 177699. PMID 8550487.
- ↑ Breitbart, M; Salamon P; Andresen B; Mahaffy JM; Segall AM; Mead D; Azam F; Rohwer F (2002). «Genomic analysis of uncultured marine viral communities». Proceedings of the National Academy of Sciences of the United States of America 99 (22): 14250-14255. Bibcode:2002PNAS...9914250B. PMC 137870. PMID 12384570. doi:10.1073/pnas.202488399.
- ↑ a b Tyson, GW; Chapman J, Hugenholtz P, Allen EE, Ram RJ, Richardson PM, Solovyev VV, Rubin EM, Rokhsar DS, Banfield JF (2004). «Insights into community structure and metabolism by reconstruction of microbial genomes from the environment». Nature 428 (6978): 37-43. PMID 14961025. doi:10.1038/nature02340. Archivado desde el original el 11 de febrero de 2009.
- ↑ Hugenholz, P (2002). «Exploring prokaryotic diversity in the genomic era». Genome Biology 3 (2): 1-8. PMC 139013. PMID 11864374. doi:10.1186/gb-2002-3-2-reviews0003.
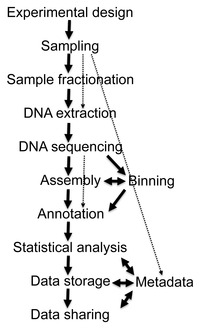
- ↑ Thomas, T.; Gilbert, J.; Meyer, F. (2012). «Metagenomics - a guide from sampling to data analysis». Microbial Informatics and Experimentation 2 (1): 3. PMC 3351745. PMID 22587947. doi:10.1186/2042-5783-2-3.
- ↑ Venter, JC; Remington K; Heidelberg JF; Halpern AL; Rusch D; Eisen JA; Wu D; Paulsen I; Nelson KE; Nelson W; Fouts DE; Levy S; Knap AH; Lomas MW; Nealson K; White O; Peterson J; Hoffman J; Parsons R; Baden-Tillson H; Pfannkoch C; Rogers Y; Smith HO (2004). «Environmental Genome Shotgun Sequencing of the Sargasso Sea». Science 304 (5667): 66-74. Bibcode:2004Sci...304...66V. PMID 15001713. doi:10.1126/science.1093857.
- ↑ Yooseph, Shibu; Kenneth H. Nealson; Douglas B. Rusch; John P. McCrow; Christopher L. Dupont; Maria Kim; Justin Johnson; Robert Montgomery; Steve Ferriera; Karen Beeson; Shannon J. Williamson; Andrey Tovchigrechko; Andrew E. Allen; Lisa A. Zeigler; Granger Sutton; Eric Eisenstadt; Yu-Hui Rogers; Robert Friedman; Marvin Frazier; J. Craig Venter (4 de noviembre de 2010). «Genomic and functional adaptation in surface ocean planktonic prokaryotes». Nature 468 (7320): 60-66. Bibcode:2010Natur.468...60Y. ISSN 0028-0836. PMID 21048761. doi:10.1038/nature09530. (requiere suscripción).
- ↑ a b c Poinar, HN; Schwarz, C; Qi, J; Shapiro, B; Macphee, RD; Buigues, B; Tikhonov, A; Huson, D; Tomsho, LP; Auch, A; Rampp, M; Miller, W; Schuster, SC (2006). «Metagenomics to Paleogenomics: Large-Scale Sequencing of Mammoth DNA». Science 311 (5759): 392-394. Bibcode:2006Sci...311..392P. PMID 16368896. doi:10.1126/science.1123360.
- ↑ Edwards, RA; Rodriguez-Brito B; Wegley L; Haynes M; Breitbart M; Peterson DM; Saar MO; Alexander S; Alexander EC; Rohwer F (2006). «Using pyrosequencing to shed light on deep mine microbial ecology». BMC Genomics 7: 57. PMC 1483832. PMID 16549033. doi:10.1186/1471-2164-7-57.
- ↑ a b Beja, O.; Suzuki, MT; Koonin, EV; Aravind, L; Hadd, A; Nguyen, LP; Villacorta, R; Amjadi, M et al. (2000). «Construction and analysis of bacterial artificial chromosome libraries from a marine microbial assemblage». Environmental Microbiology 2 (5): 516-29. PMID 11233160. doi:10.1046/j.1462-2920.2000.00133.x.
- ↑ a b Nicola, Segata; Daniela Boernigen; Timothy L Tickle; Xochitl C Morgan; Wendy S Garrett; Curtis Huttenhower (2013). «Computational meta’omics for microbial community studies». Molecular Systems Biology 9 (666): 666. PMID 23670539. doi:10.1038/msb.2013.22.
- ↑ Rodrigue, S. B.; Materna, A. C.; Timberlake, S. C.; Blackburn, M. C.; Malmstrom, R. R.; Alm, E. J.; Chisholm, S. W. (2010). «Unlocking Short Read Sequencing for Metagenomics». En Gilbert, Jack Anthony, ed. PLoS ONE 5 (7): e11840. PMC 2911387. PMID 20676378. doi:10.1371/journal.pone.0011840.
- ↑ Schuster, S. C. (2007). «Next-generation sequencing transforms today's biology». Nature Methods 5 (1): 16-18. PMID 18165802. doi:10.1038/nmeth1156.
- ↑ «Metagenomics versus Moore's law». Nature Methods 6 (9): 623. 2009. doi:10.1038/nmeth0909-623.
- ↑ a b c d e f Wooley, J. C.; Godzik, A.; Friedberg, I. (2010). «A Primer on Metagenomics». En Bourne, Philip E., ed. PLoS Computational Biology 6 (2): e1000667. PMC 2829047. PMID 20195499. doi:10.1371/journal.pcbi.1000667.
- ↑ a b Hess, Matthias; Alexander Sczyrba; Rob Egan; Tae-Wan Kim; Harshal Chokhawala; Gary Schroth; Shujun Luo; Douglas S Clark; Feng Chen; Tao Zhang; Roderick I Mackie; Len A Pennacchio; Susannah G Tringe; Axel Visel; Tanja Woyke; Zhong Wang; Edward M Rubin (28 de enero de 2011). «Metagenomic discovery of biomass-degrading genes and genomes from cow rumen». Science 331 (6016): 463-467. Bibcode:2011Sci...331..463H. ISSN 1095-9203. PMID 21273488. doi:10.1126/science.1200387.
- ↑ Qin, Junjie; Ruiqiang Li; Jeroen Raes; Manimozhiyan Arumugam; Kristoffer Solvsten Burgdorf; Chaysavanh Manichanh; Trine Nielsen; Nicolas Pons; Florence Levenez; Takuji Yamada; Daniel R. Mende; Junhua Li; Junming Xu; Shaochuan Li; Dongfang Li; Jianjun Cao; Bo Wang; Huiqing Liang; Huisong Zheng; Yinlong Xie; Julien Tap; Patricia Lepage; Marcelo Bertalan; Jean-Michel Batto; Torben Hansen; Denis Le Paslier; Allan Linneberg; H. Bjorn Nielsen; Eric Pelletier; Pierre Renault; Thomas Sicheritz-Ponten; Keith Turner; Hongmei Zhu; Chang Yu; Shengting Li; Min Jian; Yan Zhou; Yingrui Li; Xiuqing Zhang; Songgang Li; Nan Qin; Huanming Yang; Jian Wang; Soren Brunak; Joel Dore; Francisco Guarner; Karsten Kristiansen; Oluf Pedersen; Julian Parkhill; Jean Weissenbach; Peer Bork; S. Dusko Ehrlich; Jun Wang (4 de marzo de 2010). «A human gut microbial gene catalogue established by metagenomic sequencing». Nature 464 (7285): 59-65. Bibcode:2010Natur.464...59.. ISSN 0028-0836. PMC 3779803. PMID 20203603. doi:10.1038/nature08821. (requiere suscripción).
- ↑ a b Paulson, Joseph; O Colin Stine; Hector Corrada Bravo; Mihai Pop (2013). «Differential abundance analysis for microbial marker-gene surveys». Nature Methods 10 (12): 1200-1202. PMID 24076764. doi:10.1038/nmeth.2658.
- ↑ a b c d e f g Committee on Metagenomics: Challenges and Functional Applications, National Research Council (2007). The New Science of Metagenomics: Revealing the Secrets of Our Microbial Planet. Washington, D.C.: The National Academies Press. ISBN 0-309-10676-1.
- ↑ Mende, Daniel R.; Alison S. Waller; Shinichi Sunagawa; Aino I. Järvelin; Michelle M. Chan; Manimozhiyan Arumugam; Jeroen Raes; Peer Bork (23 de febrero de 2012). «Assessment of Metagenomic Assembly Using Simulated Next Generation Sequencing Data». PLoS ONE 7 (2): e31386. Bibcode:2012PLoSO...731386M. ISSN 1932-6203. PMC 3285633. PMID 22384016. doi:10.1371/journal.pone.0031386.
- ↑ Balzer, S.; Malde, K.; Grohme, M. A.; Jonassen, I. (2013). «Filtering duplicate reads from 454 pyrosequencing data». Bioinformatics 29: 830-836. doi:10.1093/bioinformatics/btt047.
- ↑ Mohammed, MH; Sudha Chadaram; Dinakar Komanduri; Tarini Shankar Ghosh; Sharmila S Mande (2011). «Eu-Detect: an algorithm for detecting eukaryotic sequences in metagenomic data sets». Journal of Biosciences 36 (4): 709-717. PMID 21857117. doi:10.1007/s12038-011-9105-2.
- ↑ R, Schmeider; R Edwards (2011). «Fast identification and removal of sequence contamination from genomic and metagenomic datasets». PLoS ONE 6 (3): e17288. Bibcode:2011PLoSO...617288S. PMC 3052304. PMID 21408061. doi:10.1371/journal.pone.0017288.
- ↑ a b c d e Kunin, V.; Copeland, A.; Lapidus, A.; Mavromatis, K.; Hugenholtz, P. (2008). «A Bioinformatician's Guide to Metagenomics». Microbiology and Molecular Biology Reviews 72 (4): 557-578, Table 578 Contents. PMC 2593568. PMID 19052320. doi:10.1128/MMBR.00009-08.
- ↑ Burton, J. N.; Liachko, I.; Dunham, M. J.; Shendure, J. (2014). «Species-Level Deconvolution of Metagenome Assemblies with Hi-C-Based Contact Probability Maps». G3: Genes, Genomes, Genetics 4: 1339-1346. doi:10.1534/g3.114.011825.
- ↑ a b Huson, Daniel H; S. Mitra; N. Weber; H. Ruscheweyh; Stephan C. Schuster (June 2011). «Integrative analysis of environmental sequences using MEGAN4». Genome Research 21 (9): 1552-1560. PMC 3166839. PMID 21690186. doi:10.1101/gr.120618.111.
- ↑ Zhu, Wenhan; Lomsadze Alex; Borodovsky Mark (2010). «Ab initio gene identification in metagenomic sequences». Nucleic Acids Research 38 (12): e132. PMC 2896542. PMID 20403810. doi:10.1093/nar/gkq275.
- ↑ Konopka, A. (2009). «What is microbial community ecology?». The ISME Journal 3 (11): 1223-1230. PMID 19657372. doi:10.1038/ismej.2009.88.
- ↑ a b Huson, Daniel H; A. Auch; Ji Qi; Stephan C Schuster (January 2007). «MEGAN Analysis of Metagenomic Data». Genome Research 17 (3): 377-386. PMC 1800929. PMID 17255551. doi:10.1101/gr.5969107.
- ↑ Nicola, Segata; Levi Waldron; Annalisa Ballarini; Vagheesh Narasimhan; Olivier Jousson; Curtis Huttenhower (2012). «Metagenomic microbial community profiling using unique clade-specific marker genes». Nature Methods 9 (8): 811-814. PMC 3443552. PMID 22688413. doi:10.1038/nmeth.2066.
- ↑ Pagani, Ioanna; Konstantinos Liolios; Jakob Jansson; I-Min A Chen; Tatyana Smirnova; Bahador Nosrat; Victor M Markowitz; Nikos C Kyrpides (1 de diciembre de 2011). «The Genomes OnLine Database (GOLD) v.4: status of genomic and metagenomic projects and their associated metadata». Nucleic Acids Research 40 (1): D571-9. ISSN 1362-4962. PMC 3245063. PMID 22135293. doi:10.1093/nar/gkr1100.
- ↑ Meyer, F; Paarmann D; D'Souza M; Olson R; Glass EM; Kubal M; Paczian T; Rodriguez A; Stevens R; Wilke A; Wilkening J; Edwards RA (2008). «The metagenomics RAST server – a public resource for the automatic phylogenetic and functional analysis of metagenomes». BMC Bioinformatics 9: 0. PMC 2563014. PMID 18803844. doi:10.1186/1471-2105-9-386.
- ↑ Markowitz, V. M.; Chen, I. -M. A.; Chu, K.; Szeto, E.; Palaniappan, K.; Grechkin, Y.; Ratner, A.; Jacob, B.; Pati, A.; Huntemann, M.; Liolios, K.; Pagani, I.; Anderson, I.; Mavromatis, K.; Ivanova, N. N.; Kyrpides, N. C. (2011). «IMG/M: The integrated metagenome data management and comparative analysis system». Nucleic Acids Research 40 (Database issue): D123-D129. PMC 3245048. PMID 22086953. doi:10.1093/nar/gkr975.
- ↑ a b Mitra, Suparna; Paul Rupek; Daniel C Richter; Tim Urich; Jack A Gilbert; Folker Meyer; Andreas Wilke; Daniel H Huson (2011). «Functional analysis of metagenomes and metatranscriptomes using SEED and KEGG». BMC Bioinformatics. 12 Suppl 1: S21. ISSN 1471-2105. PMC 3044276. PMID 21342551. doi:10.1186/1471-2105-12-S1-S21.
- ↑ Kurokawa, Ken; Takehiko Itoh; Tomomi Kuwahara; Kenshiro Oshima; Hidehiro Toh; Atsushi Toyoda; Hideto Takami; Hidetoshi Morita; Vineet K. Sharma; Tulika P. Srivastava; Todd D. Taylor; Hideki Noguchi; Hiroshi Mori; Yoshitoshi Ogura; Dusko S. Ehrlich; Kikuji Itoh; Toshihisa Takagi; Yoshiyuki Sakaki; Tetsuya Hayashi; Masahira Hattori (1 de enero de 2007). «Comparative Metagenomics Revealed Commonly Enriched Gene Sets in Human Gut Microbiomes». DNA Research 14 (4): 169-181. PMC 2533590. PMID 17916580. doi:10.1093/dnares/dsm018. Consultado el 18 de diciembre de 2011.
- ↑ a b c d e f Simon, C.; Daniel, R. (2010). «Metagenomic Analyses: Past and Future Trends». Applied and Environmental Microbiology 77 (4): 1153-1161. PMC 3067235. PMID 21169428. doi:10.1128/AEM.02345-10.
- ↑ Willner, D; RV Thurber; F Rohwer (2009). «Metagenomic signatures of 86 microbial and viral metagenomes.». Environmental Microbiology 11 (7): 1752-66. doi:10.1111/j.1462-2920.2009.01901.x.
- ↑ a b Ghosh, Tarini Shankar; Monzoorul Haque Mohammed; Hannah Rajasingh; Sudha Chadaram; Sharmila S Mande (2011). «HabiSign: a novel approach for comparison of metagenomes and rapid identification of habitat-specific sequences.». BMC Bioinformatics 12 (Supplement 13): S9. doi:10.1186/1471-2105-12-s13-s9.
- ↑ Fimereli, D.; Detours, V.; Konopka, T. (13 de febrero de 2013). «TriageTools: tools for partitioning and prioritizing analysis of high-throughput sequencing data». Nucleic Acids Research 41 (7): e86-e86. doi:10.1093/nar/gkt094.
- ↑ Maillet, Nicolas; Lemaitre, Claire; Chikhi, Rayan; Lavenier, Dominique; Peterlongo, Pierre. «Compareads: comparing huge metagenomic experiments». BMC Bioinformatics 13 (Suppl 19): S10. doi:10.1186/1471-2105-13-S19-S10.
- ↑ Bhusan, Kuntal Kumar; Tarini Shankar Ghosh; Sharmila S Mande (2013). «Community-analyzer: a platform for visualizing and comparing microbial community structure across microbiomes.». Genomics 102: 409-418. doi:10.1016/j.ygeno.2013.08.004.
- ↑ Werner, Jeffrey J.; Dan Knights; Marcelo L. Garcia; Nicholas B. Scalfone; Samual Smith; Kevin Yarasheski; Theresa A. Cummings; Allen R. Beers; Rob Knight; Largus T. Angenent (8 de marzo de 2011). «Bacterial community structures are unique and resilient in full-scale bioenergy systems». Proceedings of the National Academy of Sciences of the United States of America 108 (10): 4158-4163. Bibcode:2011PNAS..108.4158W. ISSN 0027-8424. PMC 3053989. PMID 21368115. doi:10.1073/pnas.1015676108.
- ↑ McInerney, Michael J.; Jessica R. Sieber; Robert P. Gunsalus (December 2009). «Syntrophy in Anaerobic Global Carbon Cycles». Current opinion in biotechnology 20 (6): 623-632. ISSN 0958-1669. PMC 2790021. PMID 19897353. doi:10.1016/j.copbio.2009.10.001.
- ↑ Klitgord, N.; Segrè, D. (2011). «Ecosystems biology of microbial metabolism». Current Opinion in Biotechnology 22 (4): 541-546. PMID 21592777. doi:10.1016/j.copbio.2011.04.018.
- ↑ Leininger, S.; Urich, T.; Schloter, M.; Schwark, L.; Qi, J.; Nicol, G. W.; Prosser, J. I.; Schuster, S. C. et al. (2006). «Archaea predominate among ammonia-oxidizing prokaryotes in soils». Nature 442 (7104): 806-809. PMID 16915287. doi:10.1038/nature04983.
- ↑ Kristensen, DM; Mushegian AR; Dolja VV; Koonin EV (2009). «New dimensions of the virus world discovered through metagenomics». Trends in Microbiology 18 (1): 11-19. PMC 3293453. PMID 19942437. doi:10.1016/j.tim.2009.11.003.
- ↑ Kerepesi, Csaba; Grolmusz, Vince (2015). «Giant Viruses of the Kutch Desert». Archives of Virology. First online. PMID 26666442. doi:10.1007/s00705-015-2720-8.
- ↑ Zimmer, Carl (13 de julio de 2010). «How Microbes Defend and Define Us». New York Times. Consultado el 29 de diciembre de 2011.
- ↑ Nelson KE and White BA (2010). «Metagenomics and Its Applications to the Study of the Human Microbiome». Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ↑ Qin, Junjie; Ruiqiang Li; Jeroen Raes; Manimozhiyan Arumugam; Kristoffer Solvesten Burgdorf (March 2010). «A human gut microbial gene catalogue established by metagenomic sequencing». Nature 464 (7285): 59-65. PMC 3779803. PMID 20203603. doi:10.1038/nature08821.
- ↑ Li, Luen-Luen; Sean R McCorkle; Sebastien Monchy; Safiyh Taghavi; Daniel van der Lelie (18 de mayo de 2009). «Bioprospecting metagenomes: glycosyl hydrolases for converting biomass». Biotechnology for Biofuels 2: 10. ISSN 1754-6834. doi:10.1186/1754-6834-2-10.
- ↑ Jaenicke, Sebastian; Christina Ander; Thomas Bekel; Regina Bisdorf; Marcus Dröge; Karl-Heinz Gartemann; Sebastian Jünemann; Olaf Kaiser; Lutz Krause; Felix Tille; Martha Zakrzewski; Alfred Pühler; Andreas Schlüter; Alexander Goesmann (26 de enero de 2011). «Comparative and Joint Analysis of Two Metagenomic Datasets from a Biogas Fermenter Obtained by 454-Pyrosequencing». En Aziz, Ramy K, ed. PLoS ONE 6 (1): e14519. Bibcode:2011PLoSO...614519J. PMC 3027613. PMID 21297863. doi:10.1371/journal.pone.0014519.
- ↑ Suen, Garret; Jarrod J Scott; Frank O Aylward; Sandra M Adams; Susannah G Tringe; Adrián A Pinto-Tomás; Clifton E Foster; Markus Pauly; Paul J Weimer; Kerrie W Barry; Lynne A Goodwin; Pascal Bouffard; Lewyn Li; Jolene Osterberger; Timothy T Harkins; Steven C Slater; Timothy J Donohue; Cameron R Currie (September 2010). «An insect herbivore microbiome with high plant biomass-degrading capacity». En Sonnenburg, Justin, ed. PLoS Genetics 6 (9): e1001129. ISSN 1553-7404. PMC 2944797. PMID 20885794. doi:10.1371/journal.pgen.1001129.
- ↑ George I (2010). «Application of Metagenomics to Bioremediation». Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ↑ a b Committee on Metagenomics: Challenges and Functional Applications, National Research Council (2007). Understanding Our Microbial Planet: The New Science of Metagenomics. The National Academies Press. Archivado desde el original el 30 de octubre de 2012. Consultado el 16 de junio de 2016.
- ↑ Simon, C.; Daniel, R. (2009). «Achievements and new knowledge unraveled by metagenomic approaches». Applied Microbiology and Biotechnology 85 (2): 265-276. PMC 2773367. PMID 19760178. doi:10.1007/s00253-009-2233-z.
- ↑ Wong D (2010). «Applications of Metagenomics for Industrial Bioproducts». Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ↑ a b Schloss, Patrick D; Jo Handelsman (June 2003). «Biotechnological prospects from metagenomics». Current Opinion in Biotechnology 14 (3): 303-310. ISSN 0958-1669. PMID 12849784. doi:10.1016/S0958-1669(03)00067-3. Archivado desde el original el 4 de marzo de 2016. Consultado el 3 de enero de 2012.
- ↑ a b c Kakirde, Kavita S.; Larissa C. Parsley; Mark R. Liles (1 de noviembre de 2010). «Size Does Matter: Application-driven Approaches for Soil Metagenomics». Soil biology & biochemistry 42 (11): 1911-1923. ISSN 0038-0717. doi:10.1016/j.soilbio.2010.07.021.
- ↑ Parachin, Nádia Skorupa; Marie F Gorwa-Grauslund (2011). «Isolation of xylose isomerases by sequence- and function-based screening from a soil metagenomic library». Biotechnology for Biofuels 4 (1): 9. ISSN 1754-6834. doi:10.1186/1754-6834-4-9. Consultado el 3 de enero de 2012.
- ↑ Jansson, Janet (2011). «Towards "Tera-Terra": Terabase Sequencing of Terrestrial Metagenomes Print E-mail». Microbe 6 (7). p. 309. Archivado desde el original el 31 de marzo de 2012. Consultado el 16 de junio de 2016.
- ↑ Vogel, T. M.; Simonet, P.; Jansson, J. K.; Hirsch, P. R.; Tiedje, J. M.; Van Elsas, J. D.; Bailey, M. J.; Nalin, R. et al. (2009). «TerraGenome: A consortium for the sequencing of a soil metagenome». Nature Reviews Microbiology 7 (4): 252. doi:10.1038/nrmicro2119.
- ↑ «TerraGenome Homepage». TerraGenome international sequencing consortium. Consultado el 30 de diciembre de 2011.
- ↑ Charles T (2010). «The Potential for Investigation of Plant-microbe Interactions Using Metagenomics Methods». Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ↑ Raes, J.; Letunic, I.; Yamada, T.; Jensen, L. J.; Bork, P. (2011). «Toward molecular trait-based ecology through integration of biogeochemical, geographical and metagenomic data». Molecular Systems Biology 7: 473. PMC 3094067. PMID 21407210. doi:10.1038/msb.2011.6.
- ↑ Lavery, T. J.; Roudnew, B.; Seymour, J.; Mitchell, J. G.; Jeffries, T. (2012). «High Nutrient Transport and Cycling Potential Revealed in the Microbial Metagenome of Australian Sea Lion (Neophoca cinerea) Faeces». En Steinke, Dirk, ed. PLoS ONE 7 (5): e36478. PMC 3350522. PMID 22606263. doi:10.1371/journal.pone.0036478.
- ↑ «What's Swimming In The River? Just Look For DNA». NPR.org. 24 de julio de 2013. Consultado el 10 de octubre de 2014.
Enlaces externos[editar]
- Focus on Metagenomics at Nature Reviews Microbiology journal website
- The “Critical Assessment of Metagenome Interpretation” (CAMI) initiative to evaluate methods in metagenomics
- Metagenomics Sequencing for microscopic life Research
| Control de autoridades |
|
|---|
 Datos: Q903778
Datos: Q903778 Multimedia: Metagenomics / Q903778
Multimedia: Metagenomics / Q903778